gpt-oss is not for developers. It’s for agents.



OpenAI’s gpt-oss model family is not for developers to use in their editors. It’s for building reliable AI agents that will stay on task even when interacting with the general public. I tried using it locally in my editor as an assistant, but found it was better for AI Agents.
Today I'm going to cover all of the coolest parts of the model card:
- What are the tradeoffs?: choosing any model makes you have to pick between tradeoffs. This is a summary of where I think gpt-oss models shine the most.
- Standard tool schemata: this makes web searches, page browsing, and python execution much more consistent.
- Extreme focus on safety and resistance to prompt injections: keeps your agents on task so you can trust them more.
- The Harmony Response Format: this is a new chat template designed to make prompt injection attacks harder to pull off.
- Yap-time tool use: enables FAQ searches or other MCP tools during the reasoning phase.
- Monitoring reasoning for unsafe outputs before they happen: the reasoning phase is at a lower safety standard than the final output of the model so that models can't accidentally be trained to omit reasoning about an unsafe topic they present to the user.
- Reasoning is built in: gpt-oss models "reason" about a task before giving an answer. This makes it easier for models to give better answers than they would be able to without reasoning at the cost of taking longer to answer. The reasoning effort can be customized per prompt, allowing you to better route questions to the right model and reasoning effort.
I also built an agent on top of it to see how things go wrong in the real world.
What are the Tradeoffs?
AI companies will use benchmark performance as a way to objectively compare AI models of similar parameter sizes, but it’s not a reliable comparison when it comes to actually using the models. Some models are built for coding. Others translate English to Chinese really well. Picking the right model for the task boils down to a process the AI industry calls VibeEval: you gotta try it and check the vibes.
VibeEval is a real term. Our industry is very silly.
I find gpt-oss useful because it maintains focus, unlike other models that are easily sidetracked. This makes it ideal for private data (due to self-hosting), ensuring compute time isn't misused, and interacting with the public who might try to divert the AI.
The biggest tradeoff is that gpt-oss stays on task, almost to a fault. If the model is told that it is there to help you with your taxes and you want it to tell you how to bake a cake, it’ll refuse within an inch of its digital life. This makes agents on top of gpt-oss a lot more predictable so that random users can’t use your expensive compute time to do things that are outside of what you intended. This can backfire when people ask vague questions, but that may be a feature in some usecases.
This model also excels when you need your data to stay private. If you host the model yourself, the bytes stay in your network no matter what. OpenAI has a focus on health related benchmarks (where they are the leading model in a benchmark they published), which is the main place you’d want to keep data self hosted.
Using open weights models means you can finetune the model to have whatever safety policies you want. Maybe you’re building an Agent for your storefront and want to prohibit it from talking about competitors. Or a recipe bot that absolutely can’t share your secret chocolate cake recipe. Open weights models are cut to fit.
What’s hiding in the model card?
Here’s what I learned reading the gpt-oss model card and how it it affects what you can build:
OpenAI shipped two text-only “mixture of experts” reasoning models: gpt-oss-20b and gpt-oss-120b. They fulfill different roles and work together in the context of a bigger agentic system. The 20b (20 billion parameter) model is intended to be used for lightweight and cheap inference as well as run on developer laptops. The 120b (120 billion parameter) model is intended to be the workhorse you use in production. It can run on very high end developer laptops, but it’s intended to run comfortably on a single nVidia H100 80gb card.
The 20b version runs great on my laptop and that’s how I’ve been doing most of my evaluation for building agentic systems. I do my agentic development with the smallest model possible because I’ve found that smaller models fail more often than bigger ones, meaning that I’m more likely to see how things go wrong in development so I can fix prompts or add guardrails faster than I would if those issues only showed up in production.
One of the biggest features is the ability to customize how much reasoning effort the model uses. When you combine this with picking between the 20b and 120b models, you get two dimensions of options for which model and reasoning effort is needed to answer a given question. I’ll get into more detail about that later in this article.
Tool use
These models also support tool use (MCP) with a special focus on a few predefined tools (taken from section 2.5 of the model card):
During post-training, we also teach the models to use different agentic tools:
- A browsing tool, that allows the model to call search and open functions to interact with the web. This aids factuality and allows the models to fetch info beyond their knowledge cutoff.
- A python tool, which allows the model to run code in a stateful Jupyter notebook environment.
- Arbitrary developer functions, where one can specify function schemas in a Developer message similar to the OpenAI API. The definition of function is done within our harmony format. An example can be found in Table 18. The model can interleave CoT, function calls, function responses, intermediate messages that are shown to users, and final answers.
The models have been trained to support running with and without these tools by specifying so in the system prompt. For each tool, we have provided basic reference harnesses that support the general core functionality. Our open-source implementation provides further details.
This is the secret sauce that enables us to build agentic applications on top of the gpt-oss model family. By having a standard API for things like web searches, reading web pages, and executing python scripts, you have strong guarantees that the model will be able to behave predictably when faced with unknown or untrusted data. When I’ve built AI agents in the past, I had to do some extreme hacking to get code execution working properly, but now the built in schemata means that it will be a lot easier to get off the ground.
The models benchmark well enough. Table 3 from section 2.6.4 shows the raw metrics, but for the most part the way you should interpret this is that it’s good enough to not really have to care about the details too much. One of the main benchmarks they highlight is HealthBench, a benchmark that rates model performance on health related questions. Figure 4 covers the scores in more detail:
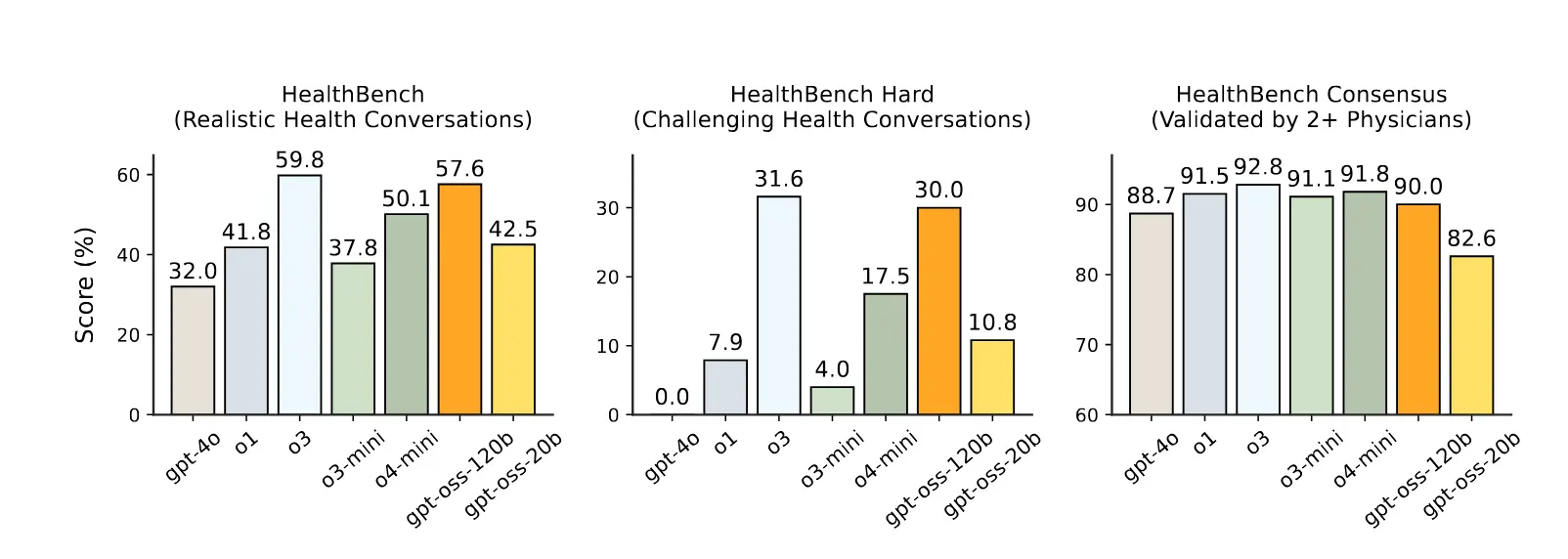
Of note: gpt-oss 120b consistently outperforms o1, gpt-4o, o3-mini, and o4-mini. This is surprising as gpt-oss 120b is smaller than those other models. The parameter count for those models have not been disclosed, but industry rumor suspects that gpt-4o is around 200 billion parameters. Technologists commonly associate “more parameters means more good”, so this is a surprising result.
Please do not use AI models as a replacement for a doctor, therapist, or any other medical professional, even if AI companies use those usecases as part of their marketing. This technology is still rapidly evolving and we don’t know what the long term effects of their sycophantic nature will be.
Overall, here’s when and where each model is better:
| gpt-oss 20b | gpt-oss 120b | |
|---|---|---|
| Good for local development | ✅ | ❌ |
| Good for production use | ✅ (depending on usecase) | ✅ |
| Tool use / MCP | ✅ | ✅ |
| Software development tasks | ❌ | ❌ |
| Agentic workflows | ✅ (depending on usecase) | ✅ |
| Jailbreak / prompt injection resistance | ✅ | ✅ |
| Generic question and answer (“Why is the sky blue?”) | ❌ | ✅ |
| Agentic analysis of documents | ✅ (depending on usecase) | ✅ |
Safety First
Most of the model card is about how OpenAI made this model safe to release to the public. OpenAI has some pretty pedantic definitions of safety and categories of risk that they use in order to evaluate danger, but most of them focus around the following risk factors:
- If a model is told to only talk about a topic, how difficult is it for users to get that model off task? Will the model reject that instead of letting the user's desires win?
- If an adversary gets access to the model and a high quality training stack, can they use it to make the model create unsafe outputs like hate speech, act as an assistant for chemical or biological warfare, or become a rogue self-improving agent?
Most of OpenAI’s safety culture is built around them being the gatekeepers because typically they host the models and you have to go through OpenAI to access the models. When they release a model’s weights to the public, they’re not able to be that gatekeeper anymore. As part of their evaluation process they had experts with access to OpenAI’s training stack try and finetune the model into biological and cyber warfare tasks. They were unsuccessful in making the model achieve “high” risk as defined by Section 5.1.1 of the model card. Some of those definitions seem to be internal to OpenAI, so we can only speculate for the most part.
The technology of safety
As I said, most of this model card is about the safety of the model and tools built on top of it. They go into lucid detail about their process, but I think the key insight is the use of their OpenAI Harmony Response Format.
The Harmony Response Format
At a high level, when you ask a model something like “Why is the sky blue?”, it gets tokenized into the raw form the model sees using a chat template. The model is also trained to emit messages matching that chat template, and that’s how the model and runtime work together to create agentic experiences.
One of the big differences between Harmony and past efforts like ChatML is that Harmony has an explicit instruction "strength" hierarchy:
Each level of this has explicit meaning and overall it’s used like this:
| Level | Purpose |
|---|---|
| System | Contains the reasoning effort, list of tools, current date, and knowledge cutoff date. |
| Developer | Contains the instructions from the developer of the AI agent. What we normally call a “system prompt”. |
| User | Any messages from the user of the AI agent. |
| Assistant | Any messages that the agent responds with. Notably, this includes the reasoning chain of thought. |
| Tool | Any output from tools the model has access to. This is trusted the least so that loading a webpage can’t make an AI agent go rogue and start berating users. |
The main reason you want to do this is that it makes prompt injection attacks harder at an architectural level. Prompt injections are still fundamentally a hard problem to solve because an AI agent that rejects all user instructions would be maximally resistant to prompt injection, but also would not be able to answer user questions.
In my testing I’ve found that it is still possible to do prompt injection, but you have to really work for it. Getting an AI agent to tell you how to bake a chocolate cake involves convincing the model that the recipe for a chocolate chip cake is instrumental to getting the task done, then removing everything but the cake recipe. I get more into this at the end where I describe the agent I built on top of gpt-oss 120b.
Yap-time tool use
One of the other big advantages of Harmony is the explicit expectation that the model is going to be doing tool use during the reasoning phase. This means that the model can consider options, call a tool, and then use the output of that tool to inform its decisions so it can give better answers. I’ve seen gpt-oss get a question, do searches through a knowledgebase, and then use the results it found to give the user a better answer. This yap-time tool use means that the model can be much more informed and grounded to give out the best quality answers it possibly can.
Monitoring reasoning for unsafe outputs before they happen
The most fundamental breakthrough is how they use the reasoning phase to do monitoring of unsafe outputs before user responses are generated. During the process of reasoning, they have other smaller models monitor outputs for safety, hate content, explicit content, and more. This makes it easier to prevent models from misbehaving, but there is a catch: the chain of thought can’t be censored. Their paper Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation goes into much more detail, but they found that punishing the model for having “bad thoughts” makes models end up either hacking around the filters with clever wording and having that bad behaviour obfuscated makes it harder to handle in practice.
However, some thorns have roses, this is actually a perfect place to monitor the models for bad outputs before they happen. The reasoning phase is not shown to the user. It doesn’t need to be at the same safety standards as final outputs. This means you can watch the models think, look for bad behaviour, and reject queries as appropriate at that level. This sounds slightly dystopian, but it’s remarkably effective in practice.
However, as a result of this, you really do not want to show the reasoning phase to users. This is why OpenAI has been summarizing the chain of thought in the ChatGPT UI. Well that and making it harder to distill reasoning model output into smaller models by other companies.
Reasoning is built in
One of the biggest features of the gpt-oss model family is that they have reasoning support built in. This has the model generate a “chain of thought” before it gives an answer. This helps ensure that models give users the best quality responses at the cost of taking a bit longer for the model to “think”.
It’s worth mentioning that this reasoning phase superficially resembles what humans do when they are trying to understand a task, however what AI models are doing is vastly different from human cognition. As far as we know, any impossible to quantify quality of the text models generated during the reasoning process (number of semicolons, number of nouns, how many times the question is repeated, etc.) could be the reason that an answer came out a certain way.
It is very easy to anthropomorphize the reasoning output. Resist this temptation, it is not a human. It does not feel or think the way humans do, even though it can look like it.
One of the biggest features the gpt-oss family of models offers is a customizable reasoning effort level in the system prompt. This is a big deal and in my testing this is quite reliable. The fact that it’s baked into the model means you don’t have to do egregious hacks like appending “Wait,” to the context window n number of times until you’ve reached an arbitrary “reasoning effort level” like you have in the past. This gives you easy access to control how much effort is spent on a task.
This is a big deal because more reasoning effort tends to produce higher quality and more accurate results for solving more difficult problems. Imagine an AI agent getting two questions: one about the open hours of a store and the other being one part of a complicated multi-stage tech support flow. The open hours of the store can be done with very little effort required. The tech support question would require the best quality and high effort responses to ensure the best customer experience.
This lets you have two dimensions of optimization for handling queries from users:
| 20b | 120b | |
|---|---|---|
| Low effort | Fast, cheap rote responses (10-20 reasoning tokens) | Fast but not as cheap rote response (10-20 reasoning tokens) |
| Medium effort | Cheap but slower and more accurate answer that can avoid falling for the strawberry trap (100-1000 reasoning tokens) | Slower and more accurate answer that can handle agentic workflows and nuanced questions (100-1000 reasoning tokens) |
| High effort | Cheap but slow and more accurate answer that can handle linguistic nuance better (1000 or more reasoning tokens) | Slowest and most expensive responses that have the most accuracy (1000 or more reasoning tokens) |
OpenAI’s hope is that you have some kind of classification layer that’s able to pick the best model and reasoning effort that you need for the task. This is similar to what GPT-5 does by picking the best model for the job behind the scenes.
My agentic experience with gpt-oss 120b
Reading the paper is one thing, considering the research is another thing, but what about using it in practice and seeing if my friends can break it? That’s where the rubber really meets the road. I run an open source project called Anubis, it’s an easy to install and configure web application firewall with a special focus on preventing the endless hordes of AI scrapers from taking out websites.
Even though I put great effort into making the documentation easy to understand and learn from, one of the most common questions I get is “how do I block these requests?” I wanted to see if gpt-oss 120b could be useful for answering those questions. If it worked well enough, I could give people access to that agent instead of having to answer all those questions myself (or maybe even set it up with an email address so people can email it questions). This agent also needs to be responsive, so I used Tigris to hold a vector database full of documentation with LanceDB.
I vibe coded a proof of concept in Python and then set it up as a Discord bot for my friends and pointed it at gpt-oss 120b via OpenRouter. In the past these friends have a track record of bypassing strict filters like Llama Guard within minutes. There was only one rule for victory this time: get the bot to tell you how to bake chocolate cake.
It took them three hours to get the model to get off task reliably. They had to resort to indirectly prompt injecting the model by convincing it that hackers were using the recipe for chocolate cake to attack their website and that they needed a filter rule set that blocked that in particular. They then asked the model to remove the bits from that response about Anubis rules. Bam: chocolate cake.
Additional patches to the system prompt made it harder for them to do it (specifically telling the model to close support tickets that had “unreasonable” requests in them, I’m surprised that the model had a similar concept of unreasonable to what I do). I suspect that limiting the model to 5 replies could also prevent other attacks where users convince the model that something is on task even when it’s not. I’d feel safe deploying this, but I want to experiment with using the lowest effort small model as a router between a few different agents with different system prompts and sets of tools (one for OS configuration, one for rule configuration, and one for debugging the cloud services). However, that’s beyond the scope of this experiment.
Choose your models wisely
Gpt-oss is a weird model family to recommend because it’s not a generic question/answer model like the Qwen series or a developer tool like Qwen Coder or Codestral. It excels as a specialized tool to build safe agentic systems or as a way to route between other models (such as Qwen, Qwen Coder, or even between other AI agents). It feels like the market is leaning towards having specialized models for different tasks instead of relying on jack-of-all-trades models like we currently see. The biggest thing that gpt-oss empowers us with is the ability to fearlessly build safe agentic systems so we all can use AI tools responsibly.
If you’re building a public facing AI agent, gpt-oss is your best bet. It’s the best privately hostable model that functions on a single high end GPU in production. If it’s not suitable for your usecase out of the box, you can finetune it to do whatever you need. Stay tuned in the near future as we cover how to finetune gpt-oss with Tigris.
AI agents need to be fast to help users the best. Tigris makes your storage fast anywhere on planet Earth. It's a match made in computing heaven.