Build better AI agents with bucket forking


If you’re building an agent, chances are, you have or you are considering implementing a form of forking, isolating agents from one another, into your workflow to prevent “rogue” agentic behavior.
Cursor's checkpoints, for example, let developers revert code edits, while Devin takes full VM snapshots using its open‑source Blockdiff system. This speaks of both the need and complexity of having duplicate environments for agents.
While these approaches work, they’re heavy. They duplicate data and are not designed for serving a swarm of agents working in parallel in the same workspace and files. Tigris’ bucket forking changes that by giving every agent its own sandbox without copying terabytes of data.
State of the agent world
LangChain’s Harrison Chase describes four components that make an agent: planning, tool use, memory, and reflection.
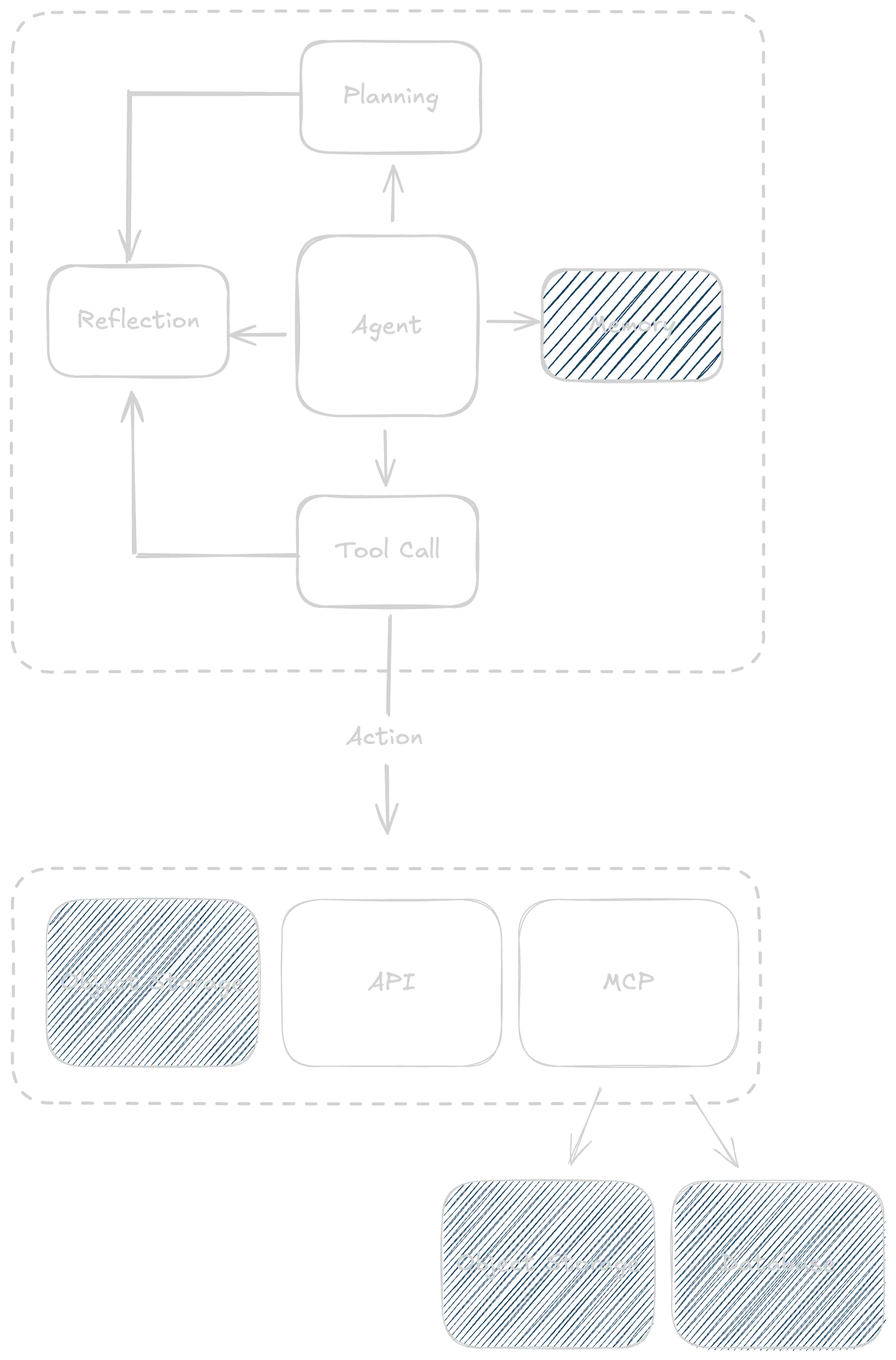
Figure 1: The four components of an agent: planning, tool use, memory, and reflection
As shown in Figure 1, agents are connected to tools to interact with their environment via custom functions, APIs or Model Context Protocol (MCP) servers. If you use a coding agent like Cursor, there are hundreds of MCP servers you can use to access infrastructure resources like databases, object storage and more.
The Tigris MCP server is a tool that allows you to use Tigris as an MCP server in your agent.
As agents become more autonomous and multi‑threaded, giving access to the same data sources raises the risk of race conditions and data corruption.
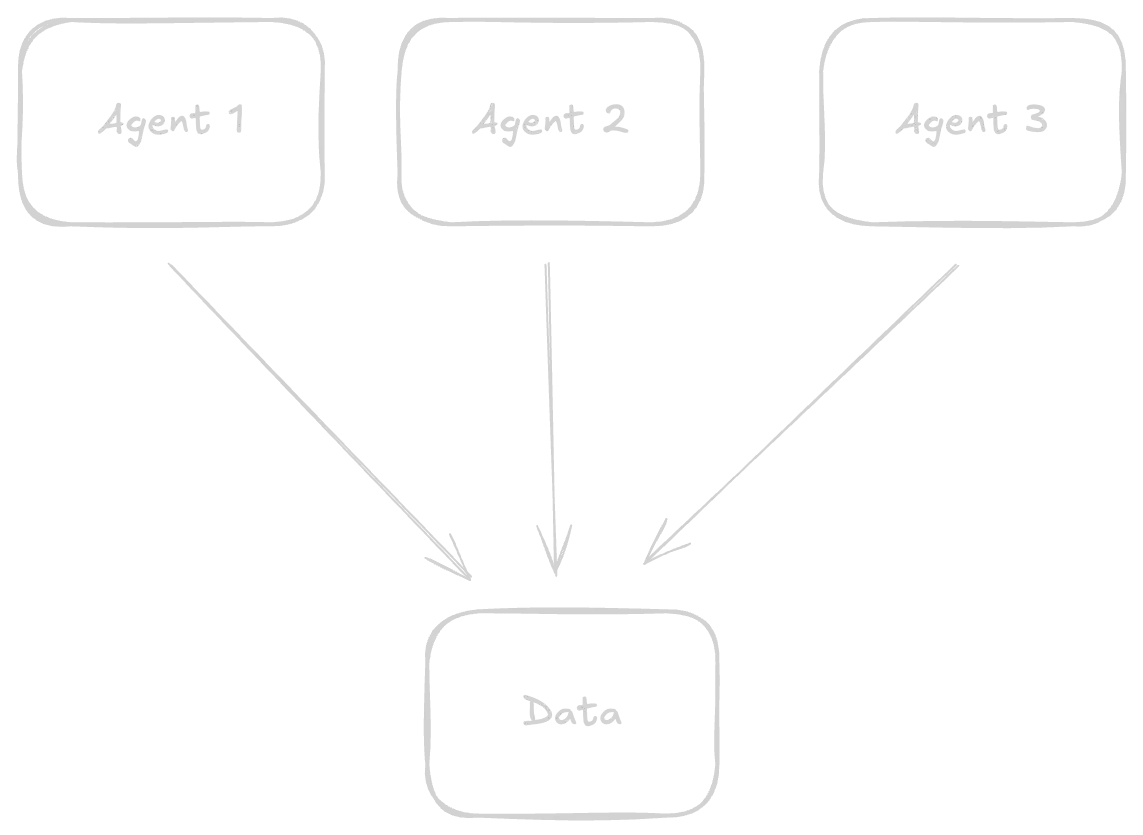
Multi-agent, single bucket
In the below example, I created an app that shows multiple agents connected to
the same bucket‑with‑snapshots bucket. The agent here has a simple task:
generate a random image and save it to the bucket under the same
original_image.png file name.
You can find the demo app code here: tigrisdata-community/bucket-forking-with-parallel-agents.
When we trigger one single agent, the file is replaced by the agent’s generation. But what happens when multiple agents all access the bucket in parallel? They overwrite files that other agents might be using. In the sample app below, the agents access the same files for generating new media, causing inconsistent behavior
The input file is overwritten by each latest agent generation. This is a simple example, but it illustrates the data consistency issue when having multiple agents share data. Let's make a better flow with bucket forks so our agents are guaranteed not to collide.
Isolated environments with bucket forking
Bucket forking makes it possible to contain that chaos. Tigris’ bucket forking allows agents to create instant isolated copies of buckets, and we believe it is an essential component to building safer agents. Some of the benefits include:
- Instant copies: child buckets are ready in milliseconds, regardless of size
- Deduplication: parent and child buckets share data up to the fork point, storing only new blocks, with no duplication and maximum efficiency
- Isolation and integrity: each agent works in a sandboxed environment, ensuring experiments never corrupt the original dataset
The code below shows how to fork a bucket using the @tigrisdata/storage SDK.
import { createBucket } from "@tigrisdata/storage";
const result = await createBucket("forked-bucket", {
sourceBucketName: "SOURCE_BUCKET_NAME",
});
Read more about bucket forking and snapshots in the docs.
Parallel agents, parallel risk
The way we build with AI is changing. Agents now operate in parallel, often sharing the same resources and environments.
As Simon Willison puts it, vibe engineering is working with AI systems as collaborators rather than tools. This shift means we don’t just write code, we orchestrate concurrent Claude Code or Cursor tabs, Background Agents, writing in the same workspace to shorten development cycles.
In the same article, Simon also stresses the importance of automated testing. Agents should be able to perform a task and test it to make sure it meets expectations. The need for safe concurrent access and testing is not specific to coding agents, and can generalize to all agents doing more than just RAG.
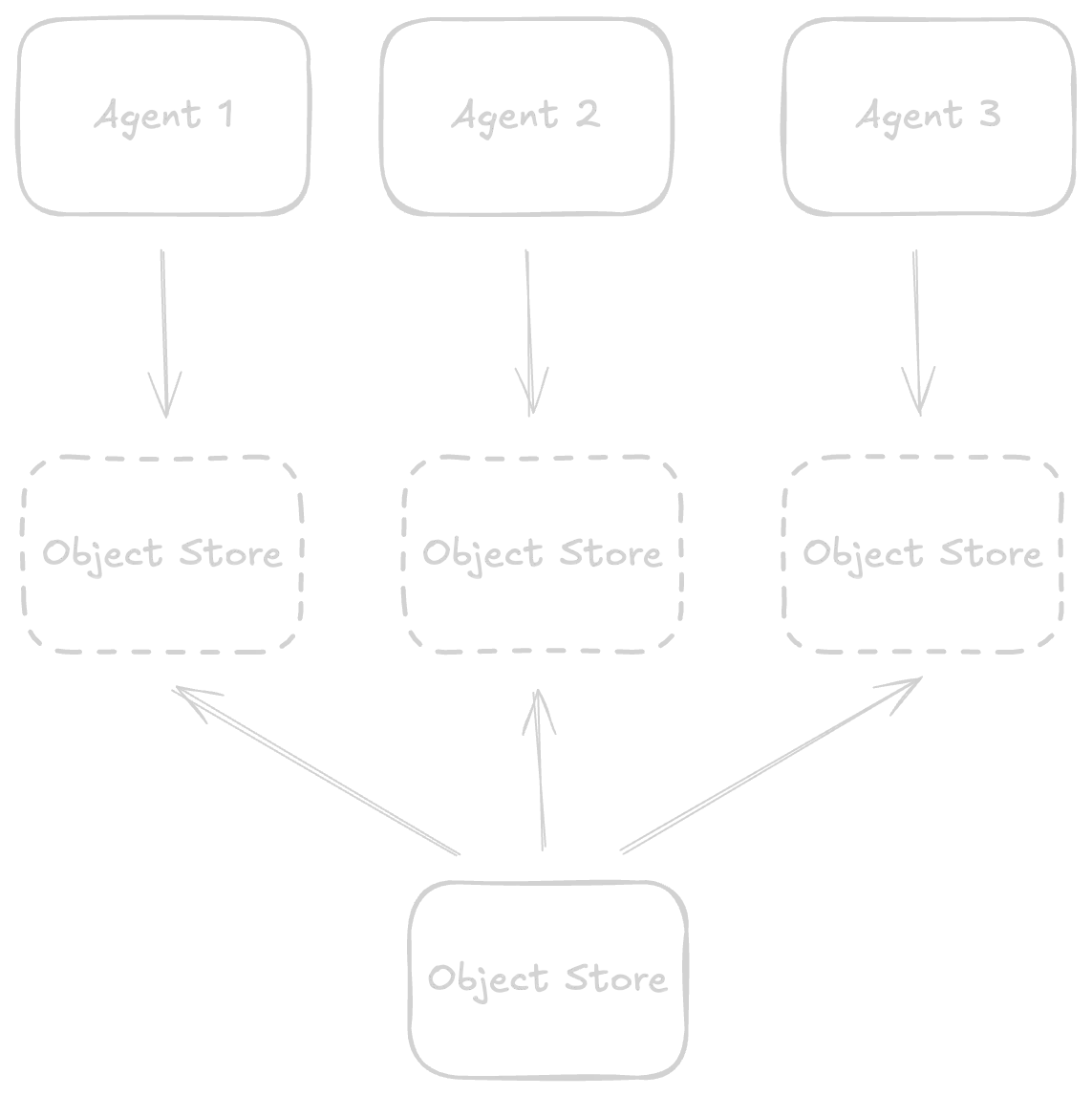
In Tigris, every forked bucket inherits the data from its parent, but remains isolated until merged. Agents can experiment freely without risking the original dataset. Snapshots ensure that, even if an agent corrupts its fork, the baseline remains untouched.
In my demo app, I now enable forking, and create new agents. Each agent is
linked to its own bucket fork. Now, when I run parallel generations, I can see
that my buckets are totally isolated and each bucket gets its own version of
original_image.png file, without ever altering my source bucket.
This means AI agents can scale: you can have dozens of agents performing tasks at once, without breaking your source of truth.
In code, the SDK allows you to create a fork from a source bucket, then save
your files using the put function and specifying the target bucket.
// /api/fork/route.ts
import { NextRequest, NextResponse } from "next/server";
import { createBucket } from "@tigrisdata/storage";
export async function GET(req: NextRequest) {
const url = new URL(req.url);
const sourceBucketName = url.searchParams.get("sourceBucketName");
const forkBucketName = url.searchParams.get("forkBucketName");
if (!sourceBucketName || !forkBucketName) {
return new NextResponse("Missing required params", { status: 400 });
}
const forkResult = await createBucket(forkBucketName, { sourceBucketName });
if ((forkResult as any)?.error) {
console.error("Error creating bucket fork:", (forkResult as any).error);
return new NextResponse(
`Failed to create bucket fork: ${(forkResult as any).error}`,
{ status: 500 }
);
}
return NextResponse.json({ ok: true, data: forkResult });
}
// /api/generate/route.ts
import { NextRequest, NextResponse } from "next/server";
import { put } from "@tigrisdata/storage";
export async function POST(req: NextRequest) {
// image gen init ...
const url = new URL(req.url);
const bucketName = url.searchParams.get("bucketName");
const targetFileName =
url.searchParams.get("targetFileName") || "original_image.png";
if (!bucketName) {
return new NextResponse("Missing bucketName", { status: 400 });
}
try {
// Generate a random image from a text-only prompt
const outMime = "image/png";
const outBuffer = new Uint8Array(); // generated image bytes
const blob = new Blob([outBuffer], { type: outMime });
// Save to requested target file (agent-specific)
const putResult = await put(targetFileName, blob, {
contentType: outMime,
config: { bucket: bucketName },
});
if (putResult?.error) {
console.error("Error replacing image in Tigris:", putResult.error);
return new NextResponse(`Failed to upload image: ${putResult.error}`, {
status: 500,
});
}
return NextResponse.json({ ok: true, data: putResult });
} catch (err: any) {
return new NextResponse(
`Failed to upload image: ${err?.message || "unknown"}`,
{
status: 500,
}
);
}
}
Conclusion
Agents are meant to work in parallel and be autonomous. Because of the unpredictability this implies, AI agents are in need of safe environments and sandboxes for testing and experimenting, and that’s what bucket forking offers.
Are you building agents? Give bucket forking a try and let us know how we can make your experience using Tigris better.
Happy coding (and forking!)
Get instant, isolated copies of your data for development, testing, or experimentation.