Fearless dataset experimentation with bucket forking


A blue tiger in several parallel universes demonstrating different kinds of things that can be done with AI.
Our new feature, bucket forking, lets you make an isolated copy of your large dataset instantly with zero copying. No more colliding in shared datasets or waiting hours for bytes to copy, fork your dataset like you fork your code, and experiment away.
Experimentation enabled by bucket forking
Imagine a world where an AI company's researchers can instantly experiment with an entire, massive training dataset in object storage, without the days-long wait for copies or the uncertainty of using live data. This addresses a common pattern where developers create and then abandon numerous copies of central datasets for individual experiments, leading to significant duplication and wasted time.
We’re proposing a new workflow: create per-user (or per-run) forks of your dataset, do your experimentation and development, and then merge your updated data back into main. Just like git, and it’s as fast as forking a git repo.
When you fork a bucket, you get an isolated copy that’s a metadata reference to your original dataset. Writes to the source bucket aren’t replicated to the fork: their timelines have diverged at the moment of the fork. Tigris only stores the changes, so there’s no duplication.
Bucket forking and the scientific method
Let’s follow an experiment using the scientific method: you want your model to match the painterly aesthetic of a video game, but you aren’t sure which subset of screenshots will finetune your model best. Should you train on screenshots of the entire game? Should you make individual “experts” for deserts vs ocean scenes? Should you remove the borders and menus? Do you really need to downscale the images to 512x512 like you did in the early days of Stable Diffusion v1.5? How about the aspect ratio or greyscaling... the list goes on.
Each of these variations is an experiment, a parallel timeline for your data. Without forking, you’d need a frozen copy for each experiment for control, so you’d cull the list to minimize the number of parallel datasets. Or you’d share data across experiments and track the changes. But with forking, you can instantly make a copy so you can try all of them at once. Trivially.
We're going to make changes across the entire dataset to optimize the data for the models we want to train. Instead of making multiple copies of the dataset, we're going to use bucket forking for these experiments. But, in order to talk about that, first we need to talk about parallel universes.
Dataset experimentation with parallel universes
In the real world, datasets arrive as messy unlabeled piles of bytes that we have to make sense of in order to do useful things. As an example, let’s take our example, a dataset of Nintendo Switch game screenshots. With all this data, you could do any number of things, such as:
- Train a categorization model, or something that can take these screenshots and then learn what patterns are associated with which games so I can upload new screenshots and have them automatically categorized with the right tags for the right game.
- Train a style emulation LoRA adapter for existing text to image models that lets me create more images based on the style of individual games in that screenshot collection.
- Use a combination of OCR and other language models to distill knowledge about the screenshots into a vision model.
Today I’m going to show you how you would do this kind of experimental massaging from a bucket-forking native mindset. In my case, I want to take that dataset of Nintendo Switch screenshots and isolate things out so that I can train a Stable Diffusion LoRA on screenshots from The Legend of Zelda: Breath of the Wild. This will require the following steps:
- Importing all the jpegs into a dataset
- Filtering out all the images that aren’t from Breath of the Wild
- Synthesizing captions
- Filtering out unwanted images (IE: those in menus)
- Sending it to a GPU for training
We'll end up with four parallel timelines for our data, each a controlled lab for our experiments. Here's a sketch.

Fork 1: Data cleaning and labeling
Right now my data is a giant pile of thousands of flat files I copied off of my Switch’s SD card. It’s got a bunch of filenames that look like this:
screenshots/2022/03/03/2022030300000900-1E1800B8D04F999C436DDFE2B8CD0B81.jpg
The filenames are broken down like this:
${date}-${titleID}.jpg
So that example would be a screenshot of Dark Souls Remastered that I took in early March 2023.
I had Claude write a little shell script that broke down this input folder and renamed the files like this:
./var/switch-screenshots/train/${titleID}/${date}.jpg
Then I imported it to a Tigris bucket with a little bit of Python code:
from datasets import load_dataset
import os
BUCKET_NAME = "xe-screenshots-multiworld"
storage_options = {
"key": os.getenv("AWS_ACCESS_KEY_ID"),
"secret": os.getenv("AWS_SECRET_ACCESS_KEY"),
"endpoint_url": "https://fly.storage.tigris.dev"
}
ds = load_dataset("imagefolder", data_dir="./var/switch-screenshots", split="train")
ds.save_to_disk(f"s3://{BUCKET_NAME}/images", storage_options=storage_options)
Then let’s freeze this state in time by creating a snapshot:
import boto3
from botocore.client import Config
def create_bucket_snapshot(bucket_name, desc):
tigris = boto3.client(
"s3",
endpoint_url="https://t3.storage.dev",
config=Config(s3={'addressing_style': 'virtual'}),
)
tigris.meta.events.register(
"before-sign.s3.CreateBucket",
lambda request, **kwargs: request.headers.add_header(
"X-Tigris-Snapshot", f"true; desc={desc}"
)
)
return tigris.create_bucket(Bucket=bucket_name)["ResponseMetadata"]["HTTPHeaders"]["x-tigris-snapshot-version"]
create_bucket_snapshot(BUCKET_NAME, "imported dataset from the disk")
And then we can make sure it’s there by listing all the snapshots:
def list_snapshots_for_bucket(bucket_name):
tigris = boto3.client(
"s3",
endpoint_url="https://t3.storage.dev",
config=Config(s3={'addressing_style': 'virtual'}),
)
tigris.meta.events.register(
"before-sign.s3.ListBuckets",
lambda request, **kwargs: request.headers.add_header("X-Tigris-Snapshot", bucket_name)
)
return tigris.list_buckets()
for snapshot in list_snapshots_for_bucket(BUCKET_NAME)['Buckets']:
name, desc = snapshot["Name"].split("; desc=")
snaptime = snapshot["CreationDate"].strftime("%s")
print(f"name={name} time={snaptime} desc=\"{desc}\"")
That returns something like this:
{'name': '1760036788104497556', 'time': '1760054788', 'desc': 'imported dataset from the disk'}
So we can use this snapshot to create a fork of the bucket:
def create_bucket_fork(bucket_name, from_bucket, snapshot_id=None):
tigris = boto3.client(
"s3",
endpoint_url="https://t3.storage.dev",
config=Config(s3={'addressing_style': 'virtual'}),
)
tigris.meta.events.register(
"before-sign.s3.CreateBucket",
lambda request, **kwargs: (
request.headers.add_header("X-Tigris-Fork-Source-Bucket", from_bucket),
)
)
if snapshot_id is not None:
tigris.meta.events.register(
"before-sign.s3.CreateBucket",
lambda request, **kwargs: (
request.headers.add_header("X-Tigris-Fork-Source-Bucket-Snapshot", snapshot_id),
)
)
tigris.create_bucket(Bucket=bucket_name)
botw_only_bucket = f"{BUCKET_NAME}-botw"
create_bucket_fork(botw_only_bucket, BUCKET_NAME, "1760036788104497556")
And then make some helpers to load the dataset from that fork:
from datasets import load_from_disk
def load_timeline(bucket_name):
return load_from_disk(f"s3://{bucket_name}/images", storage_options=storage_options)
def save_timeline(ds, bucket_name):
ds.save_to_disk(f"s3://{bucket_name}/images", storage_options=storage_options)
Something cool about the bucket forking flow is that this treats your bucket paths as part of your public API. You don’t need to think about where you load the dataset from the bucket, because that’s not the variable that changed. You’re just loading the data from a different timeline.
Filtering
From here we can filter everything that isn’t from Breath of the Wild out of the
dataset. According to
the Switchbrew wiki,
the title ID for Breath of the Wild is F1C11A22FAEE3B82F21B330E1B786A39. Let’s
set this as a global variable and then filter everything else out:
BOTW_TITLE_ID = "F1C11A22FAEE3B82F21B330E1B786A39"
ds = load_timeline(botw_only_bucket)
ds = ds.filter(lambda x: ds.features['label'].names[x['label']] == BOTW_TITLE_ID)
print(f"filtered dataset size: {len(ds)}")
save_timeline(ds, botw_only_bucket)
Then we can make a snapshot of the bucket in this state:
botw_only_snapshot_id = create_bucket_snapshot(botw_only_bucket, "Dataset filtered down to only images of Breath of the Wild")
Fork 2: Caption Synthesis
I use this dataset for other training projects so I don't want to apply the captions to the common dataset. I want to leave the underlying / central data the same and add my captions in its own little fork. Let’s start by diverging the timeline for captioning and make a fork:
caption_bucket = f"{BUCKET_NAME}-captions"
create_bucket_fork(caption_bucket, botw_only_bucket, botw_only_snapshot_id)
ds = load_timeline(caption_bucket)
From here we add an empty column for the text caption (our training workflow
will require this to be called text):
text_data = [""] * len(ds)
ds = ds.add_column("text", text_data)
Then we can generate high-quality captions using a few-shot process. For this I went into Breath of the Wild and captured some screenshots I’ll use to make my own high quality captions as examples for the language model. I’m including a few images in my dataset, capturing the following scenarios/scenes:
- Link in a grassy field
- Link in the desert
- Link paragliding through the air
- Menu interactions
These base captions will help “ground” the model so it creates more captions like my examples. For the captioning I’m going to be using gemma3:4b on a local device, but you can use whatever model you want.
This is where you can fork the timeline to diverge!
I’ll set up Ollama in another cell:
!pip install ollama
import ollama
OLLAMA_MODEL = "gemma3:4b"
OLLAMA_URL = "http://192.168.2.12:11434"
llm = ollama.Client(host=OLLAMA_URL)
llm.pull(OLLAMA_MODEL)
And then my base image captioning code will look like this:
Longer code block
response = llm.chat(model=OLLAMA_MODEL, messages=[
{
"role": "system",
"content": "You are an expert image captioner assigned to caption images about video games. When given an image, make sure to only include the image caption, nothing else.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/gerudo_desert.JPG")]
},
{
"role": "assistant",
"content": "in_BOTW The Gerudo Desert, Link is facing the camera, A mountain range in the distance, A shrine surrounded by palm trees",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/menus.JPG")]
},
{
"role": "assistant",
"content": "in_BOTW A menu showing Link's armor sets, Desert Voe Trousers, Inventory menu",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/lanaru_rocks.JPG")]
},
])
When I give it an example image, such as this:
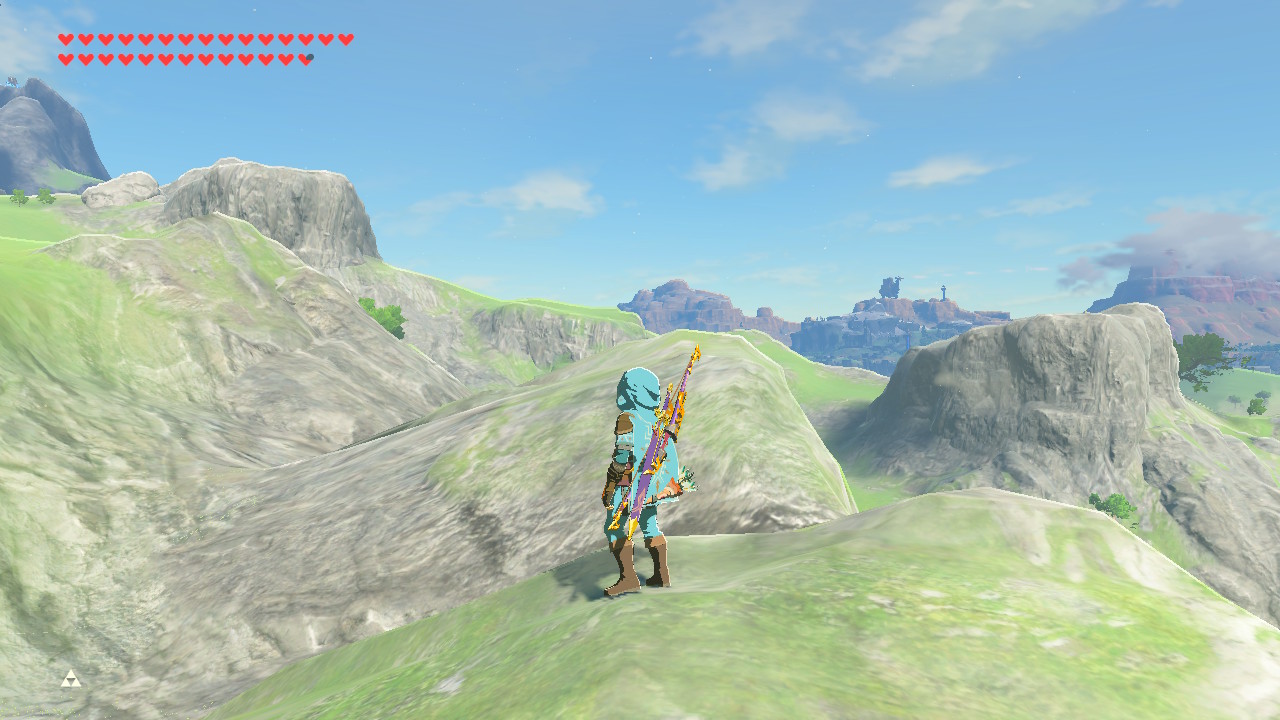
I get a caption like this:
in_BOTW Link standing atop a hill in Hyrule, overlooking the landscape
This is good enough for me! Now to apply this to the entire dataset:
Longer code block
from base64 import b64encode
from io import BytesIO
def load_image_b64(fname):
with open(fname, "rb") as fin:
data = fin.read()
b64 = b64encode(data).decode("utf-8")
return b64
def pil_to_b64(image):
buf = BytesIO()
image.save(buf, format="JPEG")
return b64encode(buf.getvalue()).decode("utf-8")
def fabricate_caption(row):
response = llm.chat(model=OLLAMA_MODEL, messages=[
{
"role": "system",
"content": "You are an expert image captioner assigned to caption images about video games. When given an image, make sure to only include the image caption, nothing else.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/gerudo_desert.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW The Gerudo Desert, Link is facing the camera, A mountain range in the distance, A shrine surrounded by palm trees",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/menus.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW A menu showing Link's armor sets, Desert Voe Trousers, Inventory menu",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/lanaru_rocks.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW Link standing atop a series of rocks overlooking the landscape, blue partially cloudy sky",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/paragliding.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW Link paragliding over Hyrule field with mountains in the distance, an empty field of green grass is below him"
},
{
"role": "user",
"content": "Please caption this image",
"images": [pil_to_b64(row["image"])],
},
])
row["text"] = response.message.content
return row
ds = ds.map(fabricate_caption)
Perfect! Now let’s save it:
save_timeline(ds, caption_bucket)
caption_snapshot_id = create_bucket_snapshot(caption_bucket, "Added captions to the dataset")
caption_snapshot_id
Fork 3: Better captioning and different models
When I was looking through the dataset I noticed that some of the captions weren’t ideal, so I thought that I should redo them by changing the prompting theory to be closer to what Stable Diffusion XL natively prefers. However, I don't know if this new method will be any better. I want to preserve the old captions so I can compare them. Let’s see if a different captioning method will work better. I want to preserve the first experiment so I can compare; thus I forked the bucket.
better_caption_bucket = f"{BUCKET_NAME}-better-captions"
create_bucket_fork(better_caption_bucket, botw_only_bucket, botw_only_snapshot_id)
I took one of the few-shotted images and asked Gemini Pro 2.5 to describe it as a Stable Diffusion prompt:

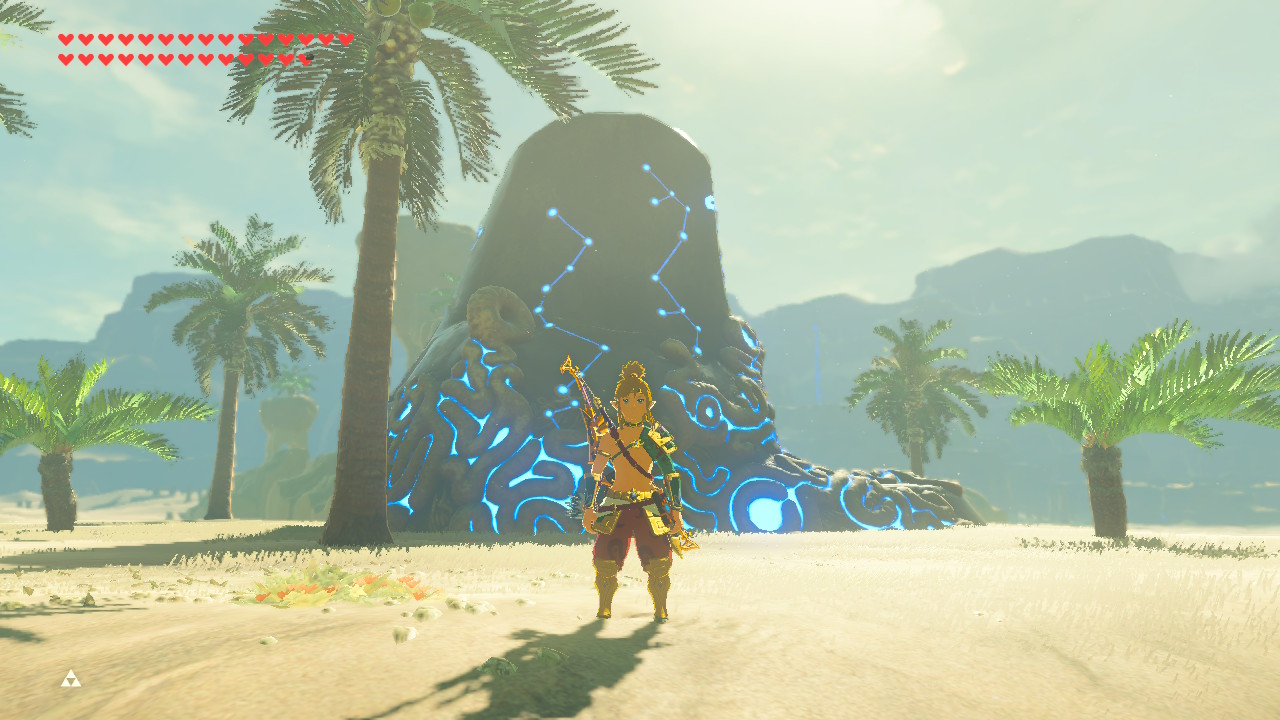

This is much better than the older prompts and will likely get better results when doing training. I made a new timeline forked from before I made captions the first time:
ds = load_timeline(better_caption_bucket)
text_data = [""] * len(ds)
ds = ds.add_column("text", text_data)
I replaced all of the few-shotted captions in my notebook with Gemini generated captions like that.
Longer code block
def fabricate_caption(row):
response = llm.chat(model=OLLAMA_MODEL, messages=[
{
"role": "system",
"content": "You are an expert image captioner assigned to caption images about video games. When given an image, make sure to only include the image caption, nothing else.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/gerudo_desert.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW masterpiece, best quality, cinematic screenshot from The Legend of Zelda: Breath of the Wild, (view from behind of Link:1.2) wearing golden pauldrons and Gerudo desert gear, standing in a sun-drenched desert oasis with palm trees, a massive ancient stone monolith Sheikah Shrine covered in (glowing blue neon constellations and intricate patterns:1.3), wide shot, painterly cel-shaded art style, vibrant colors, strong shadows, epic fantasy, atmospheric, distant rocky mesas under a bright blue sky with wispy clouds.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/menus.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW masterpiece, best quality, 8k, official art, high-resolution screenshot from The Legend of Zelda: Breath of the Wild, video game inventory menu screen, a grid of armor icons and a detailed item description box for \"Desert Voe Trousers\", on the right a full-body 3D model of the character Link wearing the Desert Voe armor set with a golden bow, clean UI design, cel-shaded art style, fantasy, adventure game.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/lanaru_rocks.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW masterpiece, best quality, 8k, cinematic screenshot from The Legend of Zelda: Breath of the Wild, (view from behind of Link:1.2) wearing blue armor and a blue hood, standing on a lush green hilltop, looking out over a vast, expansive landscape of rolling green hills, rocky cliffs, and distant mountains under a bright blue sky with scattered clouds, wide shot, painterly cel-shaded art style, vibrant colors, strong shadows, epic fantasy, atmospheric.",
},
{
"role": "user",
"content": "Please caption this image",
"images": [load_image_b64("./few_shot/botw/paragliding.JPG")],
},
{
"role": "assistant",
"content": "in_BOTW masterpiece, best quality, 8k, cinematic screenshot from The Legend of Zelda: Breath of the Wild, (view from behind of Link:1.2) soaring through the air with a paraglider over a vast, sunlit green valley, with distant, majestic mountains in the background under a clear blue sky, dynamic action shot, painterly cel-shaded art style, vibrant colors, epic fantasy, atmospheric, sense of freedom."
},
{
"role": "user",
"content": "Please caption this image",
"images": [pil_to_b64(row["image"])],
},
])
row["text"] = response.message.content
return row
ds = ds.map(fabricate_caption)
Then I investigated a few image-caption pairs:

masterpiece, best quality, 8k, cinematic screenshot from The Legend of Zelda: Breath of the Wild, (close up of Zelda):1.3, Gerudo champion, wearing Gerudo clothing, a golden headband and earrings, standing in the shade of a stone building in the Gerudo Desert, golden accents, detailed armor, warm lighting, cinematic, fantasy art.

masterpiece, best quality, 8k, interior shot, cozy scene from The Legend of Zelda: Breath of the Wild, Link and Impa preparing a meal over a crackling campfire inside a simple wooden shelter, with a rustic interior decorated with furs and wooden furniture, warm lighting, cooking ingredients, charming atmosphere, fantasy setting, vibrant colors, detailed environment.
This would be much better to train a LoRA on!
Fork 4: Resizing to train Stable Diffusion
Now that I have the images and captions, I want to start optimizing the image size for the model I want to train. This requires a destructive action across every image in the dataset.
When training Stable Diffusion, you generally want your images to meet specific resolutions:
- If you are using Stable Diffusion v1.5, you want the resolution of your images to add up to 1024 (eg 512x512, 768x384, etc.)
- If you are using Stable Diffusion XL, you want the resolution of your images to add up to 2048 (eg 1024x1024, 1344x768, etc.)
Actions across the entire dataset like this are a poster child for making a fork:
resized_bucket = f"{BUCKET_NAME}-512-centre-crop"
create_bucket_fork(resized_bucket, better_caption_bucket)
Based on the fact that all of my images are 1280x720, without upscaling them the best model to train against is Stable Diffusion v1.5. This means I need to centre crop the images to 512x512. Another experiment/fork could involve resizing the images to something like 768x384 to get closer to the original 16:9 aspect ratio. Here's how I resized all the images in the dataset:
from PIL import Image
def center_crop_resize(image, size=512):
width, height = image.size
min_side = min(width, height)
left = (width - min_side) // 2
top = (height - min_side) // 2
right = left + min_side
bottom = top + min_side
cropped = image.crop((left, top, right, bottom))
return cropped.resize((size, size), Image.Resampling.LANCZOS)
def resize_row(row):
row["image"] = center_crop_resize(row["image"])
return row
ds = load_timeline(resized_bucket)
ds = ds.map(resize_row)
Once I’m done, I just save the data to Tigris so I can try using it in training:
save_timeline(ds, resized_bucket)
snapshot_id = create_bucket_snapshot(resized_bucket)
Et voila! I can do my Stable Diffusion v1.5 training fearlessly.
Thinking with portals
In the process of working on this, we ended up with four different forks of our dataset. These are:
- The base dataset (mostly unaltered from the original Switch SD card)
- A version of it that only has screenshots of Breath of the Wild
- A version of it with a first pass at captioning
- A version of it with a better pass at captioning
- A version of the better pass at captioning but cropped and resized for Stable Diffusion training
See how this maps more cleanly to the experimental process? The artifacts of
this are easily visible and nothing was deleted in the process. This is how you
think with portals bucket forking!
From here all you have to do is submit your dataset to be trained. I’d suggest doing some more filtering before training such as removing rows with keywords like “menu”, “message”, or “text” in them, but this is something you can freely experiment with on your own. If you want to check out the dataset I filtered out when I was writing this post, I posted a copy of it to Hugging Face.
- The raw set of all of my Switch screenshots: XeIaso/switch-screenshots.
- The Breath of the Wild screenshots with better captions: XeIaso/botw-screenshots-captioned.
- The centre cropped screenshots with better captions: XeIaso/botw-screenshots-captioned-square.
I plan to train Stable Diffusion on it when I get the time.
The important thing to keep in mind is that this model of being able to reset things and fork the timeline when they go awry or you want to try multiple different things. What if you tried using a different model for describing the screenshots? What if you tried a different few shot prompting flow? What if your filtering logic was different? Each of those can be cleanly forked off and tried in their own little universes without impacting any of the data. All of the data in the source bucket remains safe in Tigris even though we’ve been whittling it down as things get filtered out.
See how this maps to the normal experimental workflow we do with things like chemistry, physics, and other natural sciences? If at first you don’t succeed by changing a variable you think will work out, travel back in time, destroy the universe you were just in, and try again.
As our dataset complexity grows, isolation like this and tight controls over data provenance have become so much more important and painful to manage manually. Tigris’ bucket snapshots and forks make it trivial for you to grab a dataset from cold storage and then do whatever transformations you want without the fear of overwriting something important.
Tigris lets you take your data, store it globally, and then fork it fearlessly; all without egress fees. Try it today!